 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow deep is your encoder: an analysis of features descriptors for an autoencoder-based audio-visual quality metric
Mar 24, 2020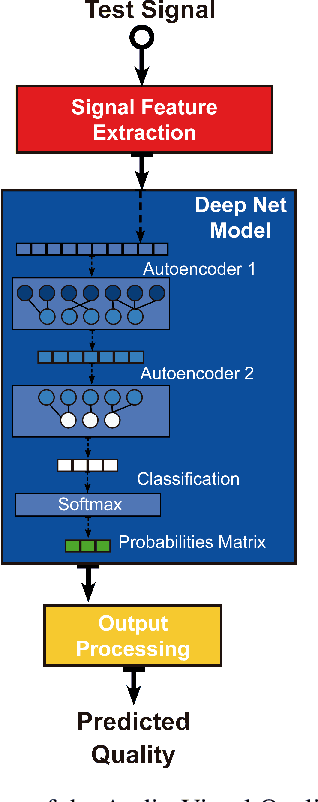
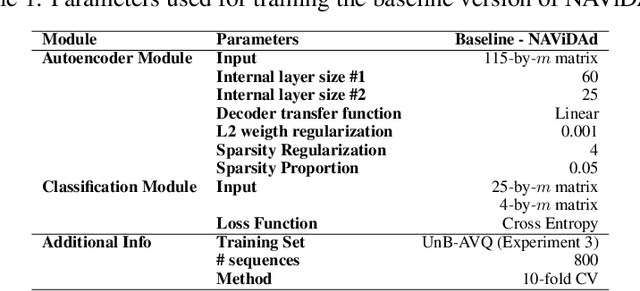
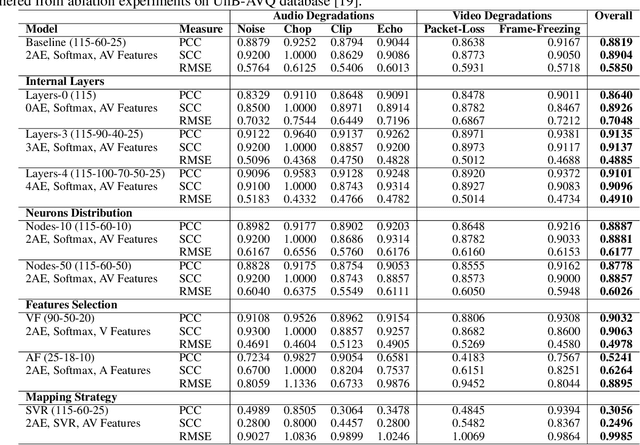
The development of audio-visual quality assessment models poses a number of challenges in order to obtain accurate predictions. One of these challenges is the modelling of the complex interaction that audio and visual stimuli have and how this interaction is interpreted by human users. The No-Reference Audio-Visual Quality Metric Based on a Deep Autoencoder (NAViDAd) deals with this problem from a machine learning perspective. The metric receives two sets of audio and video features descriptors and produces a low-dimensional set of features used to predict the audio-visual quality. A basic implementation of NAViDAd was able to produce accurate predictions tested with a range of different audio-visual databases. The current work performs an ablation study on the base architecture of the metric. Several modules are removed or re-trained using different configurations to have a better understanding of the metric functionality. The results presented in this study provided important feedback that allows us to understand the real capacity of the metric's architecture and eventually develop a much better audio-visual quality metric.
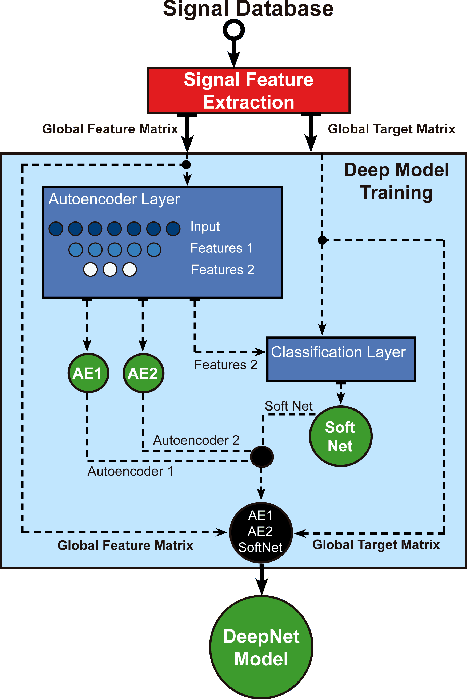
NAViDAd: A No-Reference Audio-Visual Quality Metric Based on a Deep Autoencoder
Feb 04, 2020



The development of models for quality prediction of both audio and video signals is a fairly mature field. But, although several multimodal models have been proposed, the area of audio-visual quality prediction is still an emerging area. In fact, despite the reasonable performance obtained by combination and parametric metrics, currently there is no reliable pixel-based audio-visual quality metric. The approach presented in this work is based on the assumption that autoencoders, fed with descriptive audio and video features, might produce a set of features that is able to describe the complex audio and video interactions. Based on this hypothesis, we propose a No-Reference Audio-Visual Quality Metric Based on a Deep Autoencoder (NAViDAd). The model visual features are natural scene statistics (NSS) and spatial-temporal measures of the video component. Meanwhile, the audio features are obtained by computing the spectrogram representation of the audio component. The model is formed by a 2-layer framework that includes a deep autoencoder layer and a classification layer. These two layers are stacked and trained to build the deep neural network model. The model is trained and tested using a large set of stimuli, containing representative audio and video artifacts. The model performed well when tested against the UnB-AV and the LiveNetflix-II databases. %Results shows that this type of approach produces quality scores that are highly correlated to subjective quality scores.
* 5 pages